MoE expert co-activations: Reordering inputs yields easy throughput gains.

Doubleword’s batch inference offering keeps costs down by keeping throughput high, something which isn’t easily done given the architecture of popular Mixture-of-Expert models. While MoE’s sparse expert weights make them quick to train, they also mean that at each layer of every forward each request in a batch typically requires different expert weights to be loaded. This makes inference severely memory-bandwidth bound and cuts throughput relative to dense models. However, by reordering inputs so that similar prompts batch together, we can overlap the experts needed and reduce the number of unique experts loaded per forward. Simply using an embedding model to reorder requests before inference can cut expert loads by approximately 15%, achieving a free throughput gain with no model or kernel changes.
To demonstrate this, we’ll take Qwen/Qwen3.5-35B-A3B (top-8 experts from 256, 40 MoE layers) and record which experts are loaded over prefill and each decode step. We do this for 256 decode tokens and for 1000 typical prompts from mlabonne/open-perfectblend. Using this information, we can then arrange the prompts into batches with preferable co-location (“oracle batches”). We do this using a greedy algorithm, starting with one example and accumulating sequences which add the least new experts to the set of those loaded over the course of the batch’s inference. Compared with batches formed from randomly selected examples, our expert-aware oracle clusters have 21.3% less expert loads! A “load” here is an instance of an expert weight being loaded from HBM into compute units.
While we don’t know which experts a sequence will actually activate, we can approximate it effectively by observing similarities between prompts. Clustering examples into batches based on their embedding’s cosine similarity is a good heuristic for expert activations, with BAAI/bge-small-en-v1.5 clustered batches saving 12.4% of expert loads (achieving 58.3% of our oracle ceiling).
We can achieve even more of the ceiling by training BGE to better fit the geometry of expert activations. The aim is for the cosine similarity of BGE’s embeddings for two sequences’ to resemble the (Jaccard) overlap in expert choices for the two sequences. After training on 30,000 Perfectblend examples, examples ordered by the model have 15.6% expert loads than the random ordering (capturing 73.6% of the oracle-defined ceiling).
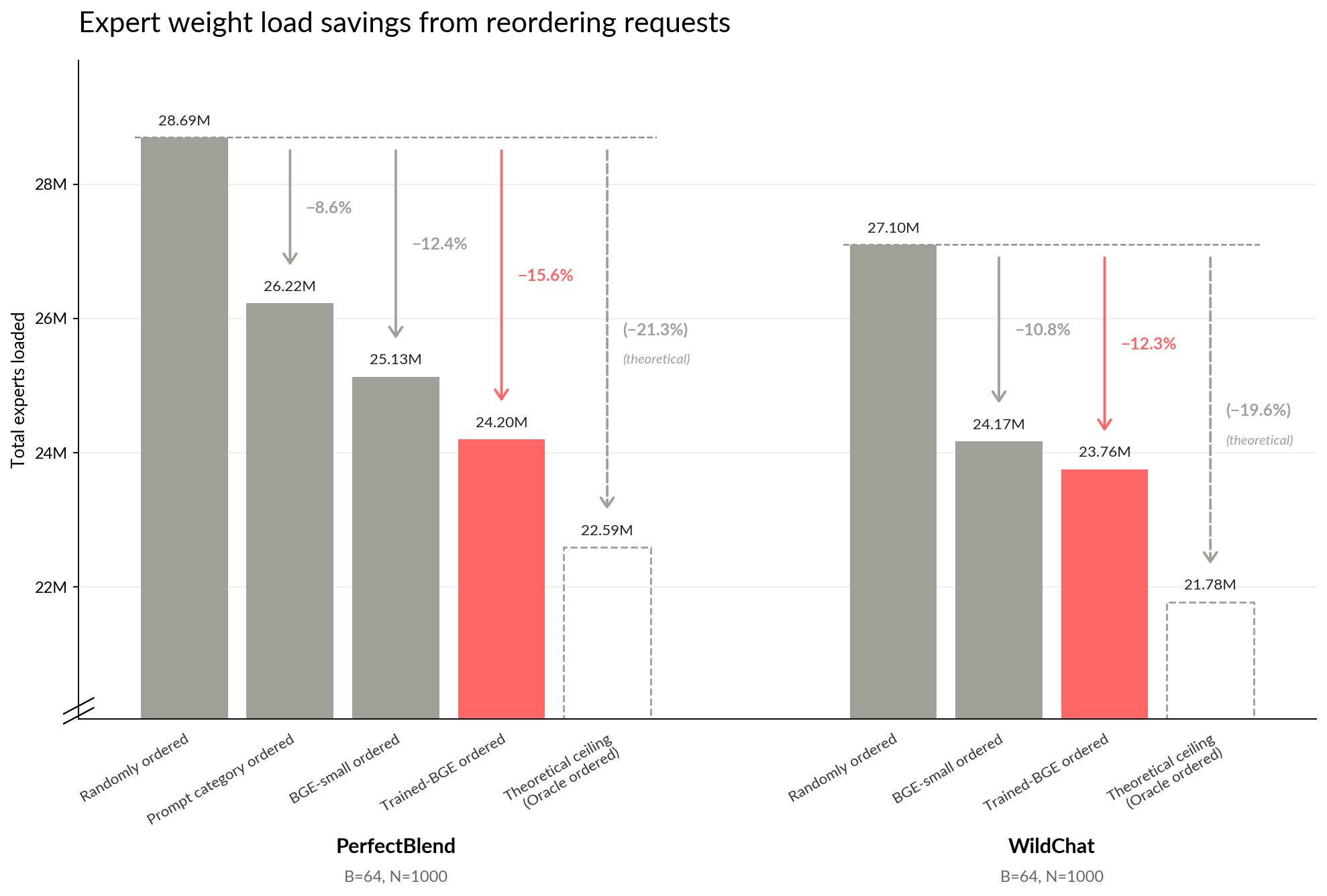
Given that Perfectblend is an amalgamation of some distinct prompt categories (chat/code/math/instructions), we also plotted a category-ordered baseline to demonstrate that the trained model is in fact doing more than just batching chat and math prompts separately, obtaining roughly 2x as many savings as the category baseline. This explains why savings persist when evaluating out-of-domain. Wildchat is a chat-prompt only dataset, with homogeneity that means there’s less inter-cluster variance to exploit. Despite the ‘harder’ ordering task, both BGE (10.8% reduction in loads) and the trained model (12.3% reduction) do well at predicting which experts’ specific sequences will activate. Performance is expectedly weaker from both models, although the training is still useful in aiding expert prediction outside of the trained domain.
These savings also translate into wall-clock time savings. For Qwen3.5-35B-A3B, MoE operations only make up ~43% of those in a given forward, which corresponds to the trained model going from 12.3% of expert loads saved to a 5.4% wall-clock saving.
The ratio between dataset size and batch size dictates how homogenous your clusters typically are, as there are more highly-similar examples to put together into batches. Wildchat reflects this - increasing the number of examples clustered into batches of 64 from 1,000 to 5,000 enhances load savings from 12.3% to 17.11%. This speedup is something Doubleword’s platform is ideally suited to leverage, as we can observe large numbers of incoming requests and batch them as homogeneously as possible.
Production systems typically use expert parallel setups where experts are sharded across ranks. The demonstrated load saving mechanism does carry over to this setting, but the extent to which it can be exploited depends on how the experts are sharded. The amount of loads saved by batching varies by expert, meaning speedups will vary by rank. However as faster ranks ultimately await the slower ones, the exploitable speedup is that of the rank housing the experts with the fewest loads saved. One solution to this would be co-locating experts so that each rank handles a single batch as much as possible. To prevent other ranks being idle, you would want batches which consist of multiple domain-specific minibatches which are each then routed to wholly occupy a single rank.
An interesting subsequent investigation could determine whether prompts can be ordered continuously (rather than into batches) so that the change in experts between each prompt is minimal. This would better reflect how continuous batching systems progressively slide new examples in and ameliorate the batch-transition point combination of dissimilar experts, with the added benefit of removing any noise added by clustering methods. Alternatively, further training on the current approach could close the remaining 5.7pp of expert loads from the ceiling for Perfectblend, or derive a model that better generalises to datasets like Wildchat. While we’ve capped decodes at 256 tokens, there’s nothing constraining the technique to fixed cluster assignments - re-clustering against currently in-flight requests during decoding would extend the benefit to longer generations, where cluster coherence naturally decays as prompts diverge.
In summary, reordering inputs to better match a model’s expert-routing structure is a free optimization - no kernel or architecture changes are needed, just a clustering step upstream of the inference engine. Across in-domain and out-of-domain workloads, a trained encoder can capture 12-15% of expert loads versus random ordering, a free throughput gain in the memory-bandwidth dominated MoE serving domain.
@misc{doubleword-moe-expert-coactivations,
title = {MoE expert co-activations: Reordering inputs yields easy throughput gains.},
author = {Josh Cowan},
year = {2026},
howpublished = {Doubleword Blog},
url = {https://blog.doubleword.ai/moe-expert-coactivations},
}